因为工程实践里需要实现语义分析的功能,关于如何语义分析,我也是一头雾水。最近花了点时间,依据贝叶斯原理,针对工程实践,写了一个分类器,效果还阔以~~ 哈哈
写在前头
在研一上学期的时候,学院里分配了一个工程实践项目,我所在的4人组选了基于语义的搜索引擎这个课题,项目主页:https://github.com/willstudy/SearchEngine。目前项目进展到语义分析模块了,我就查阅了相关资料,然后根据项目的数据集,定制了一个贝叶斯分类器。
贝叶斯定理
老是说我第一眼看到这个定理的时候,完全没有任何印象。其实这个定理最早出现在本科所学的概率论中的,好惭愧,竟然被我忘光了。。。
贝叶斯定理主要是:当知道A发生的情况下,B发生的概率 P( B | A) 时, 求 B 发生的条件下,A发生的概率 P( A | B ),其公式为:

这个公式在生活很有用,我们在不知不觉中可能就用到了它。比如说,在街上看到一个黑种人,我们很自然的联想到,他可能来自非洲。在得出判断的过程中,我们就用到了贝叶斯分类器的思想。
贝叶斯分类器
在生活,经常会进行各种各样的分类,比如说文档归类、网页分类等,使用的分类方法称之为分类器。大多数分类器都是基于贝叶斯定理展开的,大致过程如下:
- 确定需要分出的类别:Y1,Y2,Y3…
- 对目标分类对象进行特征**(X1,X2,X3…)**提取
- 计算这些特征的先验概率,即P(X1|Y1),P(X2|Y1),P(X1|Y2)…
- 根据贝叶斯公式,计算待分类的后验概率,即P(Y1|X1,X2,X3…)
贝叶斯计算后验概率的公式如下:

这里我会根据工程实践中的数据集,进行一步步的分析。
数据集的描述
我的这个工程实践,是基于语义的搜索引擎,主要做关于美食做法方面的搜索。其所有的数据都是从美食天下网爬到的数据,在此给贵网站带来的不便,致以深深的歉意。其中每条记录主要包含如下字段:
菜的标题|网站的URL|菜的介绍|菜图片的URL|菜的食材|菜的类型|菜的做法步骤|菜的小窍门
大约共3.5W条记录。
分类器的原型
老师说过,软件工程的第一步是需求分析。那我第一步从需求分析写起。项目需要的分类器的需求描述如下:
用户输入一句话,比如:
1 | 西红柿炒鸡蛋 |
分类器能判断用户是想检索菜名类别、食材类别还是工艺类别。因为我选用的分词工具对这句话分割的结果如下:
1 | 西红柿 炒 鸡蛋 |
如果只是简单的字符串匹配,那么它很可能既属于菜名,又可能属于工艺,又可能属于食材。这时候就需要一个分类器,对分词的结果进行分类处理。
所以这个分类器的输入是:分词后的词组,输出是: 类别。
分类器的设计
根据上文中提到的贝叶斯分类器的设计步骤,我做了如下工作:
1、类别确定
分类器的类别: 菜名、食材、工艺
2、特征提取
我这里提取的特征,是对分词工具一些简单的修改,然后使用它分词之后的结果作为特征。比如
西红柿炒鸡蛋 的特征为 西红柿 炒 鸡蛋,而 排毒养颜的菜 的 特征为 排毒 养颜 菜
3、计算先验概率
这一步花了我很多时间,首先,我用python把之前爬到的3.5W条记录,再次处理了一下。利用python把每个字段对应的信息提取出来。比如说,我共提取了36924条菜名、食材、工艺,分别单独存放在 title.txt、material.txt、type.txt 中。
然后利用分词工具对上述三个文件 title.txt、material.txt、type.txt 再次处理了一下,把它们分割成词条,分别单独存放在了 splite_title.txt、splite_material.txt、splite_type.txt 中。
然后这一步比较简单,我利用Python统计,上述分割后的文件中词条的词频,然后分别除以每个类别的词条总数。用python处理 split_title.txt 文件描述如下:
1 | #coding=utf-8 |
最后会生成 percent_title.txt percent_material.txt percent_type.txt 文件。
最后一步,我这三个概率文件归并在一起,形成最后的先验概率集合。用python描述如下:
1 | #coding=utf-8 |
**有一种情况需要特别说明:**当一个词条只出现在一个类别,在其他类别没有出现时,它的先验概率计算:
1 | laplace_title = 1 / ( title_num * 2 ) |
没错,这就是我采用的Laplace平滑方法。
4、计算后验概率
利用贝叶斯公式,分别求出 菜名、食材、工艺的后验概率。这一步我用PHP语言写的,因为我们的分词工具是SCWS的PHP扩展,半推半就的使用PHP写出了这个分类器。其PHP语言描述如下:
1 |
|
具体做法把先验概率加载进内存,分别查出每个特征的先验概率 probe_title probe_material probe_type,然后根据每个类别的初始比重,进行连乘,分别求出每个类别的概率,描述如下:
1 | if( array_key_exists( $word, $gather_container ) ) |
这个分类器遇到了一些问题,我会在下部分提出,并写下我的解决方法。
分类器存在的问题及我的解决方案
关于Laplace平滑
若一个特征词只出现在某个分类中,比如说 金玉满堂,它只出现在菜名中,正常的计算结果概率为:
金玉满堂: 6.48718780409e-05 0.00 0.00
这样的计算会使一旦出现这个词,其他种类的概率立马变成0了,因为与0相乘,结果为0。这大大的降低了分类器的准确性。
解决措施:将其他类没有出现该词条的概率设为 1 / ( 2 * 词条总数 ),也称为Laplace平滑。最后 金玉满堂 的先验概率如下:
金玉满堂:6.48718780409e-05 1.70892262682e-06 1.00831862869e-06
关于乘积指数下溢的情况
因为词条种类共仅92W条,所以有的词条概率很低,那么它们进行贝叶斯公式的相乘时,就会造成丢失精度的情况。这种情况下我效仿了一位博主的做法,先对先验概率进行取自然对数,然后进行相乘。
关于特征值之间的独立性
因为贝叶斯公式要求各个特征之间是相互独立的,也就是说 西红柿 炒 鸡蛋 它们之间是没有关系的。然而实际上是有关系,它们之间的关联度,很大程度上觉得了分类结果。这里我的优化措施是,对最后的分类概率再进行平滑,若之间的概率相差不超过2倍,我就多返回一个分类,这样在丢失精度的情况下,同时保证了语义分析。
写在最后
这个分类器难度在于,对实际问题的抽象。如果知道了哪些是我们需要的特征值,怎么计算先验概率,那么剩下的工作就是数据的处理了。这个贝叶斯分类器效果其实还不错,值越小,说明越接近某个分类。大部分情况下,能得出我想要的分类结果。如下图所示:
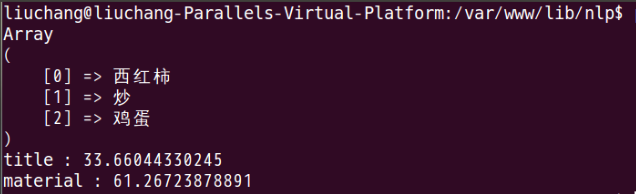
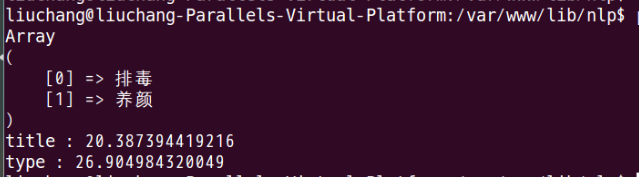
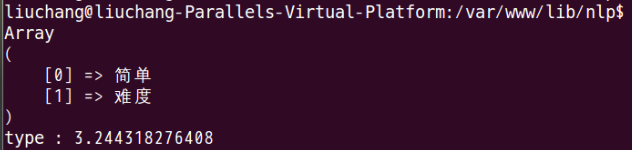
为了写这个分类器,连续写了3天代码,脸上长了几个痘痘。。。最后感谢那些提供我资料来源的博主们~~
参考
算法杂货铺——分类算法之朴素贝叶斯分类(Naive Bayesian classification)
朴素贝叶斯分类及其在文本分类、垃圾邮件检测中的应用
Naive Bayes classifier