kubernetes CRI
kubernetes是一个容器编排系统,可以便捷的部署容器,它同时支持Docker和Rocket两种容器类型。然而不管是Docker还是Rocket都需要通过内部、不太稳定的接口直接集成到kubelet的源码中,这样的集成过程需要开发者十分熟悉kubelet内部原理,同时维护起来也非常麻烦。在kubernetes1.5版本中,提供了一个清晰定义的抽象层消除了这些障碍,开发者可以专注于构建他们的容器运行时,这个抽象层称作Container Runtime Interface(CRI)接口,下面介绍一下CRI这个概念。
CRI
CRI是一个插件接口,这个接口的引入使得kubelet不用重新编译的情况下管理多种容器类型。CRI主要由gRPC API和protocol buffers组成,它的架构图如下所示:
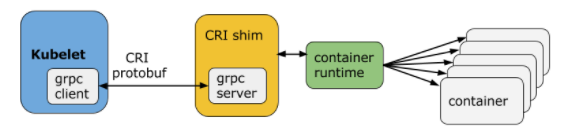
kubelet与容器运行时(或者是CRI shim)之间的通信是借助gRPC框架通过unix套接字完成的,kubelet作为client,CRI shim作为server来实现。对于docker容器而言,dockershim是kubelet的CRI shim,它负责与kubelet的gRPC客户端进行通信。
CRI shim的gRPC API主要包括Image Service和Runtime Service两部分,其中Image Service主要用来拉取、检查和删除镜像文件,而Runtime Service主要用来管理Pod和container的整个生命周期。
kubernetes拉起Docker的过程
在kubernetes中,是由kubelet组件来完成启动Docker容器的过程。在老版本(v1.5.6)的kubelet中,CRI作为一个可选项使用的,如果没有启用CRI功能,那么kubelet在执行容器时,需要经过如下调用:
1 | kubelet->docker-client(http api)->docker daemon->containerd->shim->runc |
容器启动后的进程关系如下图所示:
1 | dockerd -H fd:// |
如果启用了CRI功能,kubelet在执行容器时,则经过了下面的调用:
1 | kubelet->dockershim->docker-client(http api)->docker daemon->containerd->shim->runc |
其中containerd的架构图如下所示:
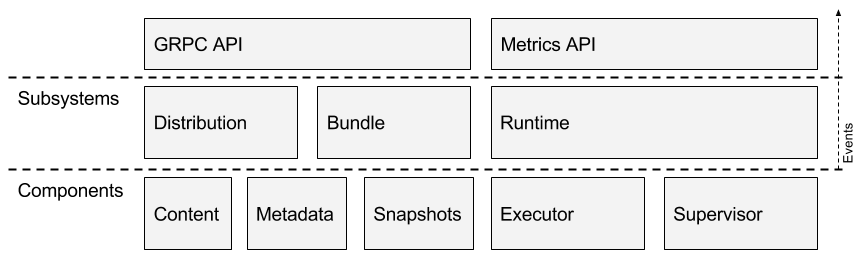
containerd与docker的关系如下图所示:

contained向上为Docker Daemon提供了gRPC接口,使得Docker Daemon屏蔽下面的结构变化,确保原有接口向下兼容,向下通过containerd-shim结合runc,实际的创建容器、运行容器,这样使得引擎可以独立升级,避免之前Docker Daemon升级导致所有容器不可用的问题。
而dockershim是一个封装了docker-client的gRPC server,它和kubelet一起启动,kubelet将创建容器的请求以gPRC的方式发送给dockershim,然后dockershim调用docker-client将创建容器的请求发送给docker daemon。
容器间如何组成一个Pod
Pod是kubernetes中的一个概念,它由一个或多个容器组成。在创建Pod的时候,过程主要如下:
- 创建一个Pod sandbox,也称为pod container,镜像是pause,它保持着net namespace打开,同一个Pod内的其他容器通过Docker的
--net=container:<id>加入到这个net namespace中,同一个Pod中容器间也共享着IPC namespace,这意味着同一个Pod内的容器可以通过localhost互相访问,同时共享同一套IPC进程间通信,在新版本的kubernetes中也实现了 pid namespace的共享。 - 创建init container(可选)
- 创建正常的container,将新container加入到pod container的net、ipc、pid(当前版本1.7.3有)namespace中,同时从 pod container 中继承来了 cgroup parent、seccomp等。
在当前版本(v1.7.3)的kubelet中,CRI已成为了缺省选项。为了进一步的降低kubernetes对容器管理的复杂性,引入了CRI-O项目,下面简单的介绍一下CRI-O。
CRI-O
kubernetes支持了Docker等多种容器类型,由于docker等容器项目变化太快,导致了kubernetes中对容器的管理部分经常修改,进而造成k8s整体的不稳定性。为了使得kubernetes从各种容器的管理工作中解脱出来,kubernetes孵化了CRI-O这个项目,CRI-O旨在不依赖传统容器引擎的前提下,使得Kubernetes调用框架可以管理和启动容器化的服务类型。
CRI-O是kubernetes CRI接口的一个实现,通过使用OCI标准来兼容各种容器类型,它是kubernetes使用docker运行环境的一个轻量级的替代方案,它允许kubernetes使用任何支持OCI标准的容器类型运行Pod。它的架构图如下:
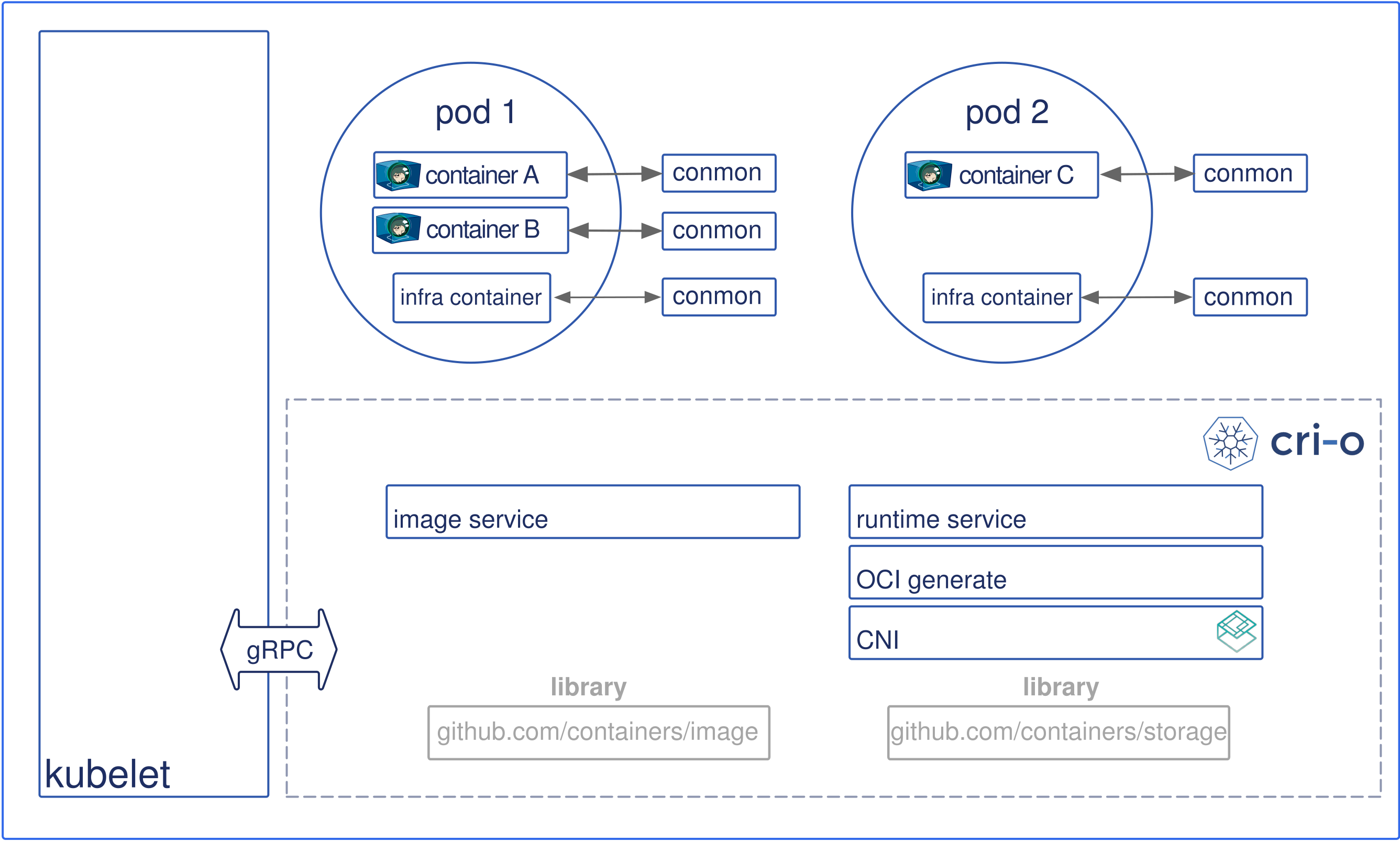
- kubernetes通过kubelet来运行一个Pod(Pod是由一个或多个容器组成的容器集合,它们共享相同的IPC、NET、PID Namespace)
- kubelet创建Pod时,通过CRI接口将请求转发给CRI-O daemon
- CRI-O通过containers/image库从registry中拉取镜像
- 下载后的镜像解压成容器的root文件系统
- 然后CRI-O通过OCI生成工具生成一份OCI配置
- CRI-O通过OCI运行工具拉起实际的container,默认的OCI运行工具是runc
- 每一个容器通过一个独立的
conmon进程来监控,这个conmon进程拥有pty终端,且是容器PID 1的进程(init) - 通过CNI接口设置Pod的网络模型,CRI-O中可以使用任何CNI插件
如果k8s使用的容器运行环境为CRI-O,那么在拉起docker类型的Pod时,不需要借助docker daemon了。
runc在整个容器的生命周期中占据了非常重要的部分,它是容器的执行引擎,下面介绍一下runc。
runc
runc概括的来说是Docker容器的执行引擎,可以通过runc这个工具创建、启动和停止Docker容器,本文从runc的概念、用法、与kubernetes的关系以及运行原理四个方面对runc进行介绍。
runc的概念
runc是libcontainer的封装,而libcontainer是对操作系统关于容器方面的一些接口。runc运行容器需要两部分信息:
- 一个OCI配置(JSON)
- 一个rootfs文件系统
这两部分信息简称bundle,其中OCI(Open Container Initiative)是一个开放容器标准组织,旨在围绕容器格式和运行时制定一个开放的工业化标准OCF(Open Container Format)。runc是由Docker贡献出来的,按照OCF的标准制定的一种具体实现。下面接单的介绍一下runc的用法。
runc的使用
runc包括两部分,首先是一个OCI配置,可以通过
1 | runc spec |
生成一份缺省的OCI配置,这里简单的浏览一下OCI中各个配置项。容器的创建除了OCI配置之外,还需要一个rootfs文件系统,这个文件系统可以通过docker export的方式获取到
1 | docker pull busybox |
有了这两部分东西之后,就可以实际的运行一个容器了,bundle包括一份OCI配置和一个rootfs,通过在bundle的目录下运行
1 | runc run busybox |
可以运行一个busybox的容器。下面演示一下不同的配置对容器实际运行的影响,包括三个方面:
- capability中的
CAP_SYS_ADMIN权限对hostname的影响 - 通过mounts中的一些选项为新容器挂载一些设备
- 通过指定namespaces中的
path将容器放在一个已有的namespace中
代码和配置放在了Github runc-demo。
capability in docker
下面介绍一下docker中的capability,可以通过
1 | capsh --print |
查看容器所拥有的capability,也可以通过
1 | docker inspect $container_id | grep Cap |
查看容器Add和Drop的capability权限。其中缺省capability记录了容器在启动时有一些默认开启的capability,在Docker文档中描述了容器全部的capability。
同时在docker容器启动时可以通过--cap-add和--cap-drop来动态的增加和去掉capability,比如为busybox容器增加SYS_PTRACE权限,这样的话,容器内可以使用ptrace这个命令了。在Docker中有一种privileged容器,通过
1 | docker run --privileged |
可以运行一个特权的容器,这个容器共享本机拥有的全部权限,这些权限定义在主机的appArmor和SELinux中。
runc run运行过程分析
通过容器标准包bundle来运行一个容器实例,容器bundle是一个文件目录,它包括容器配置的spec文件和一个rootfs文件系统,下面是运行容器时的简要流程图:
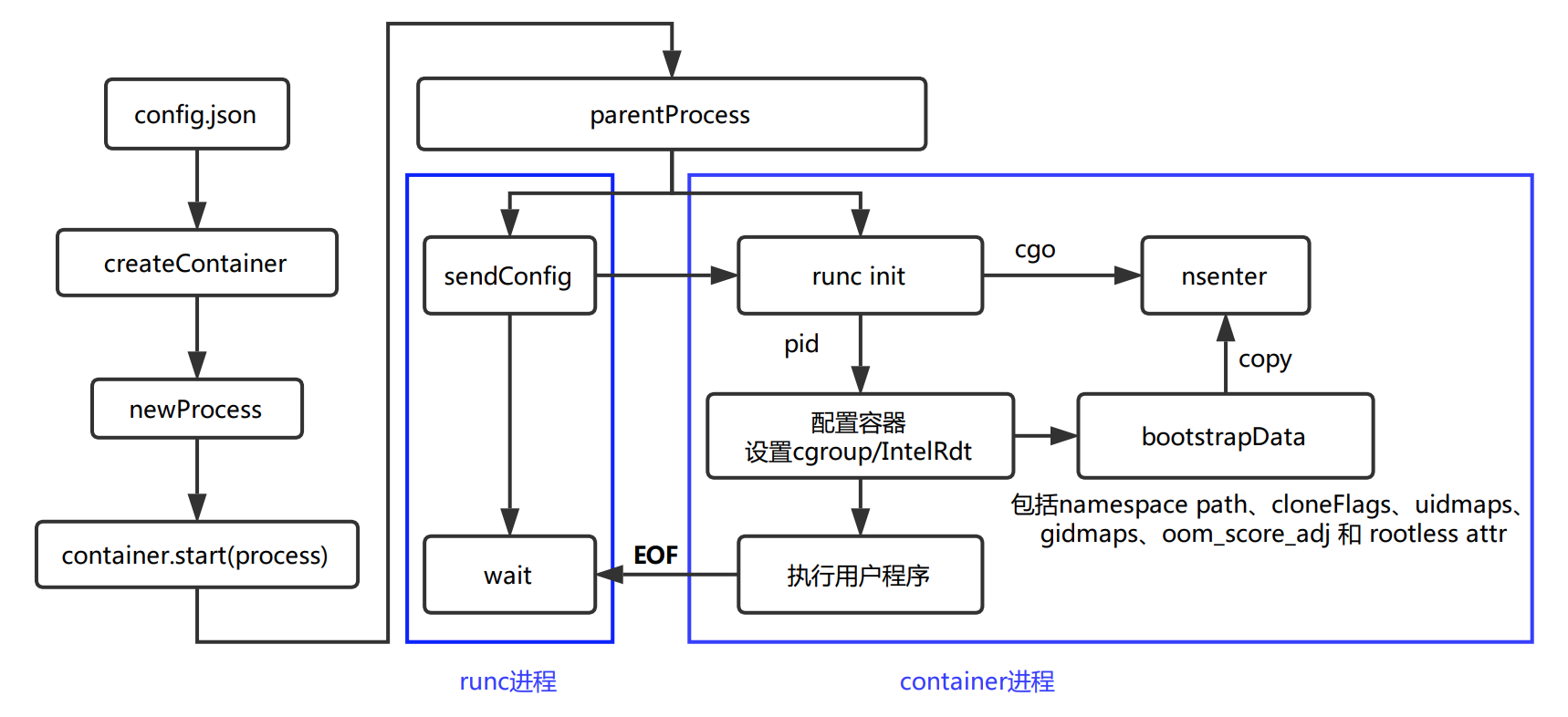
接下来简单的叙述一下容器运行的过程。
新建notifySocket
首先是新建一个通知套接字notifySocket,然后将notifySocket的信息写入到容器的OCI配置中,包括Mounts配置和进程的环境信息。
创建容器实例
createContainer:根据命令行参数和容器配置的spec文件初始化libcontainer config对象,根据命令行参数来初始化factory对象,然后factory依据libcontainer config来创建具体的容器实例。
设置notifySocket套接字
创建unixgram套接字,完成notifySocket的初始化过程
初始化runner对象,启动容器
通过传入文件描述符给容器的init进程来按需激活socket套接字,然后初始化runner对象,执行runner对象的run方法。
检查terminal
检查terminal(如果配置了detach或者action是Create,那么分配终端的时候必须设置console socket,相应的如果没有分配终端或者没有detach,则不能使用console socket)
初始化libcontainer process进程对象
newProcess:根据配置文件新建libcontainer的进程对象process,简称LP
初始化信号处理程序
初始化信号处理程序(处理SIGCHILD、SIGWINCH信号,并且转发所有的信号到这个LP进程,如果设置了notifySocket,那么可以通过它来读取容器里的systemd的通知,并且将通知转发给notifySocketHost)
设置IO,返回tty终端
- 1、如果配置文件需要创建终端的话,那么需要设置进程的0,1,2三个IO
- 2、不detach的时候,需要新建一个
console套接字对(parent和child),其中child分配给LP,用于本进程的tty对象和LP的tty通信 - 3、如果detach的话,consoleSocket会通过unix套接字的形式保持通信,runc的调用方会处理从console master收到的信息
- 4、如果detach的话,还需要继承本进程的标准IO 0,1,2 那么容器会继承runc的标准IO
- 5、设置LP进程的管道,这样可以不借助特定路径和设备的情况下,便捷的快照和恢复进程的IO。
启动容器实例
1、首先判断当前容器的状态,如果状态是STOPPED(需要初始化),那么还需要创建一个Fifo,并将属主改成容器进程的uid和gid账户
2、开始启动容器实例
(1) 新建一个parent process [initProcess(STOPPED) 或者 setnsProcess(!STOPPED)]
- 创建一个
init的套接字对,用于父子进程通信,并将childPipe分配给LP - 然后初始化执行LP进程的命令cmd,这个会调用
runc init,会勾起nsenter这个cgo程序 - 如果状态不是STOPPPED,那么不需要初始化,返回一个
setnsProcess进程 - 如果我们不执行
runc exec才可以设置fifoFd,历史原因是通过传入一个目录的dirfd来允许容器的rootfs逃逸,
对于runc exec不需要做这些,然后返回一个initProcess进程
(2) 执行parent进程(用Golang的cmd执行进程)
- 启动LP进程,将进程的Pid写入到cgroup中,如果配置了intelRdtManager,将Pid也写进Rdt中
- 将bootstrap的数据 [namespace path,clone flags,uid mapping…] 传入到管道中,让nsenter进程可以接收到
- 执行
execSetns()函数,主要等待执行LP的进程结束,并收割它的子进程,通过管道接收子进程的pid - 创建网络接口
- 将LP的配置发送给容器的初始进程
- 与容器的
init进程通信,如果程序已经procReady了,那么需要设置rlimits,
如果配置Mount Namespace的情况下,需要配置cgroup和intelRdt,然后运行启动前的钩子函数 - 如果管道传来的类型是
procHooks,需要配置cgroup和intelRdt,然后运行钩子函数。 - 最后关闭父子进程的管道描述符
(3) 收割parent进程
(4) 如果是初始化init进程的话,需要更新状态,并执行启动后的钩子函数
(5) 如果不是初始化的话,直接将容器的状态改为Running
3、等待Console的控制
4、关掉Console,并执行一些钩子函数
5、进行信号处理,分别处理SIGWINCH和SIGCHLD两种信号
6、最后将runner销毁
runc中对Namespace的应用
这里介绍一下runc中对Namespace的应用
Mount Namespace
1、容器配置中需要创建一个Mount Namespce,需要为新容器准备一个rootfs。首先是根路径’/‘的挂载,配置文件中如果配置了根路径’/'的传播属性,那么将 / 根目录以此传播属性挂载,否则以MS_SLAVE和MS_REC方式挂载。
2、将本进程也就是容器的父进程(parent)的挂载点设置成私有挂载属性,也就是将挂载属性为:shared的’/'根路径重新挂载成MS_PRIVATE, 以此来确保接下来的绑定挂载不会传播到其他Namespace中,这也可以帮助内核调用pivot_root的检查通过。
3、将rootfs绑定挂载起来,挂载属性为MS_BIND和MS_REC。
注意MS_REC含义是: 通常和MS_BIND结合使用,用来创建一个递归的绑定挂载,同时也可以和传播类型进行结合,可以递归的将挂载事件递归的传播到所有的挂载树上。
然后执行配置中的一些Mount操作,主要包括以下操作:
- 包括挂载前的操作命令 pre-mount-cmd
- 将配置文件中的一些挂载点挂载到
rootfs上,比如proc、mqueue、tmpfs等 - 挂载后的操作命令 post-mount-cmd
不需要启动dev文件的条件:/dev设备是bind类型,如果需要启动设备文件的时:
1、如果container运行在一个User Namespace那么不允许使用mknod来创建一个设备,因此只需要通过bind来进行绑定挂载操作,否则需要通过mknod在容器里面创建设备,并进行bind操作。
2、设置ptmx和/dev符号链接。
通过管道给父进程发送JSON playload,这可以使得父进程执行一些前置的钩子。在切换到新的root时,对于任何挂载操作,老的root的钩子仍然是可以用的。
然后将文件目录切换到rootfs目录下面:
- 如果配置中没有
pivotRoot操作,那么将/解挂载,通过chroot来设置新的root目录 - 如果配置中有
pivotRoot操作,那么通过pivotRoot操作来切换root目录视图。
如果需要设置dev文件的话,在切换完root目录之后,再次打开/dev/null。
User Namespace
在创建容器的时候需要初始化安全计算模型,简称seccomp,seccomp控制着容器所拥有的细粒度的操作系统权限。在完成最终的初始化seccomp之前,还需要设置容器的用户和用户组。
容器默认的执行用户情况是:
1 | {uid: 0, gid: 0, Home: "/"} |
然后根据配置文件中配置的uid和gid信息,更新容器的uid和gid信息,这里要/etc/passwd和/etc/group中的信息来判断用户设置的uid和gid的合法性。
当设置完用户和用户组id之后,在真正执行容器命令前,根据配置文件生效一下容器的Cap。
Network Namespace
根据配置文件创建网卡、配置路由。
1、主要创建两种网卡设备:loopback和veth,为容器创建网卡设备,配置网关。
2、从配置文件中读取路由策略,然后构成路由规则写入到系统中。
UTS Namespace
设置配置文件中的主机名