堆是进程空间里很重要的一部分,有效的使用堆可以很大程度上提高程序的性能,本文参考《深入理解计算机系统》简要的实现了一个内存分配器。
介绍
这是用C语言实现的一个简易的动态内存分配器,模拟动态内存的分配与回收,是本学期CSAPP课程的第五个实验。它是基于mmlib包所提供的一个存储器系统模型,在对此进行的扩充。实现了用于堆Heap内存管理的动态分配功能。
内存管理与动态分配
内存管理
是在系统层面对计算机内存的一种操作,它的基本要求是:在程序需要内存的时候,能够提供一种方式动态的分配给它;并且当应用程序不再使用时,要能回收。而操作系统动态分配的内存区域称作为堆(Heap)。
动态内存分配
动态内存分配器维护着一个进程的虚拟存储区域,称为堆(Heap),对于每个进程,内核维护着一个变量brk,它指向堆区域的顶部。栈是向下增长,而堆是向上增长的。而对于brk的改变需要系统调用,因为系统调用有很大的开销,如果让用户每次需要堆的时候都自己调用系统调用是很浪费时间的,所以需要对这堆Heap的分配进行封装。
一般做法是先分一大块堆空间,然后对分配的堆空间管理起来,提供接口,以后每次用户需要申请堆的时候,调用这些封装后的函数就行了,它们是用户层的函数,开销不大,这种封装也叫做动态内存分配器。
分配器有两种类型,一种是隐式分配,一种是显示分配。本次实现是基于显示分配的。
- 显示分配:要求应用程序显示的释放任何已分配的块,如C、C++语言
- 隐式分配:也称作垃圾回收器GC(garbage collector),是由分配器检测一个已分配块何时不再被程序所使用,并主动释放这个块,如Java、C#语言。
显示分配
本次实验是采用显示分配策略,通过一种隐式链表的形式,来链接每个空闲块以及已分配块。因为在内存分配中,不能使用复合数据类型,如队列、链表来组织这些内存块,本实验是通过对一些位进行标记,每个空闲块都有一个头部和脚部,大小为机器字长。如下图所示:
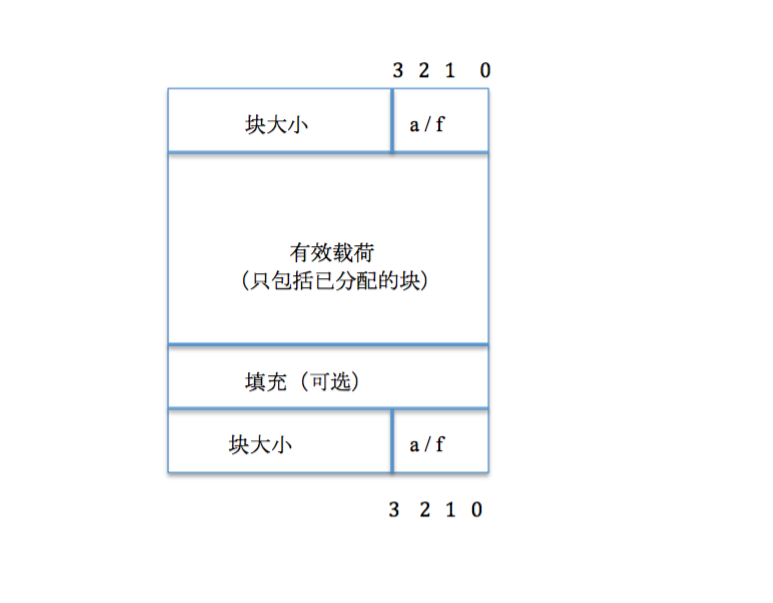
为什么要用低三位来标记一个块呢?
内部碎片与外部碎片的折中考虑,会造成不同空余位的选择, 空3位表明最小块是8个字节。余下的位可用于其他方面的标记,比如合并后的脚部,该位用于表明前一块是否是空闲的。
这样就可以定义一些宏操作用于操纵这些空闲块,如下:
1 | /* 根据块的大小和是否被标记,计算出头部和尾部的值 */ |
参考:动态内存分配
Heap的初始化
这个简易的分配器是基于mmlib提供的存储器模型,它提供了以下2个Heap管理接口:
1 |
|
分配器的简易实现
1 | /* single word (4) or double word (8) alignment */ |
性能测试
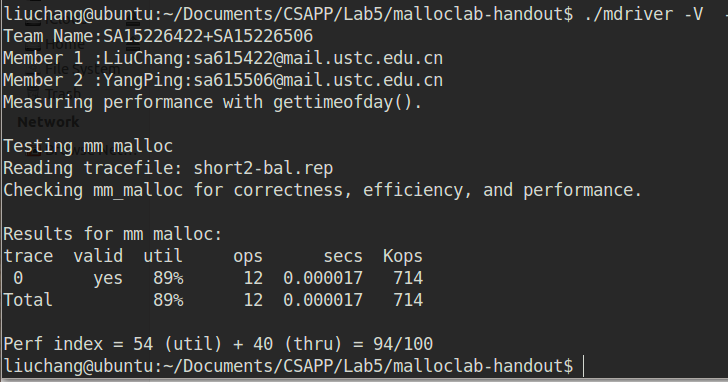
这个分配策略是根据<<深入理解计算机系统>>这本书写的,主要的不同点在于,我把书上的首次适配策略,换成了下一次适配策略。通过老师给的测试程序,结果显示下一次适配策略在本次实验中会取得更好的空间利用率和吞吐率的性能。
总结
以前学习操作系统的时候,只从概念上了解了栈的分配与回收,如今自己动手写了一下,对堆的结构有了更深刻的认识.总体来说:受益匪浅。
在实现堆空间块的标记和合并时,我懂得了学会使用某些标记位来代替一些复合数据结构如链表,达到像链表那样的功能。这样不仅节约了空间,而且非常高效。在这里向提出这种标记方法的大牛致敬_。