写在前面
-
进程基础
- 进程概念
- 进程描述符
- 进程创建
- 上下文切换
- init进程
-
进程应用
- 进程间通信
- 信号处理
- 后台进程与守护进程
- 浅谈nginx多进程模型
-
常用工具介绍
- ps: 查看进程属性
- lsof: 查看打开的文件情况
- netstat: 查看网络连接情况
- strace: 查看系统调用情况
进程基础
基础概念
进程是操作系统的基本概念之一,它是操作系统分配资源的基本单位,也是程序执行过程的实体。程序是代码和数据的集合,本身是一个静态的概念,而进程是程序的一次执行的实体,是一个动态的概念。
那在Linux操作系统中,是如何描述一个进程的呢?
进程描述符
为了管理进程,内核需要对每个进程的属性和所需要做的事情,进行清楚的描述,这个就是进程描述符的作用,Linux中的进程描述符由task_struct标识。
task_struct的数据结构是相当复杂的,不仅包含了很进程属性的字段,而且也包括了指向其他数据结构的指针。大致结构如下:
- state: 描述进程状态
- thread_info: 进程的基本信息
- mm:
mm_struct指向内存区描述符的指针 - tty:
tty_struct终端相关的描述符 - fs:
fs_struct当前目录 - files:
files_struct指向文件描述符的指针 - signal:
signal_struct所接收的信号描述 - 很多等等。。
总结一下,进程描述符完整的保存了一个进程的属性和生命周期内的数据、状态和行为,由一个复杂的数据结构task_struct来表示。
进程创建
Linux创建一个进程,大致经历的过程如下:
-
- 初始化进程描述符
-
- 申请相应的内存区域
-
- 设置进程状态、加入调度队列等等
- …
为了完整的描述一个进程,操作系统设计了非常复杂的数据结构、也申请了大量的内存空间。但是得益于写时复制技术,这些初始化操作,并没有明显的降低进程的创建速度。
写时复制技术:当新进程(子进程)被创建时,Linux内核并不会立马将父进程的内容复制给子进程,而仅仅当进程空间的内容发生变化时,才执行复制操作。写时复制技术允许父子进程读取相同的物理页,只要两者有一个试图更改页内容,内核就会把这个页的内容拷贝到新的物理页,并把这块页分给正在写的进程。
Linux中有三种系统调用可以创建进程 clone()、fork()、vfork()
- clone(): 最基础的创建进程的系统调用,可以指明子进程的基础属性(由各种FLAG标识)、堆栈等等。
- fork(): 通过clone()实现,它的堆栈指向的是父进程的堆栈,因此父子进程共享同一个用户态堆栈。fork的子进程需要完全copy父进程的内存空间,但是得益于写时复制技术,这个过程其实挺快。
- vfork(): 也是基于clone()来实现的,是历史上对fork()的优化,因为fork()需要copy父进程的内存空间,并且fork()后常常执行execve()将另一个程序加载进来,在写时复制技术之前,这种不必要的copy是代价是比较高昂的。因此vfork()实现时,会指明flag告诉clone()共享父进程的虚拟内存空间,以加快进程的创建过程。
上下文切换
概念:进程创建好之后,内核必须有能力挂起正在CPU运行的进程,并切换其他进程到CPU上执行。这种过程被称作为进程切换、任务切换或者上下文切换。
这个过程包括硬件上下文切换和软件上下文切换。
硬件上下文切换:主要通过汇编指令far jmp操作,将一个进程的描述符指针,替换为另一个进程描述符指针,并改变 eip、cs、esp等寄存器,从而改变程序的执行流。
软件上下文切换:
-
- 内存地址的切换,切换页全局目录,安装新的地址空间。
-
- 内核态堆栈的切换。
进程切换发生在schedule()函数中,内核提供了一个 need_resched 的标志,来表明是否需要重新执行一次调度。当某个进程被抢占或者更高优先级的进程进入可执行状态时,内核都会设置这个标志。那什么时候,内核会检查这个标志,来重新调度程序呢?那就是从内核态切换成用户态,或者从中断返回时。
执行系统调用时,会经历用户态与内核态的切换以及中断返回。也就是说,每一次执行系统调用,比如fork、read、write等,都可能触发内核调度新进程。
init进程
Linux进程是以树形的结构组织的,每一个进程都有唯一的进程标识,简称PID。PID为1的常常是init进程,它相对于普通进程来说,有三个特殊之处:
-
它没有默认的信号处理,因此如果发信号给init进程的话,会被它忽略掉,除非显示的注册过该信号。如果熟悉docker的同学,会观察到docker化的进程,如果按ctrl-c是没啥反应的,因为docker化的进程它们有独立的pid命名空间,第一个新创出的进程,pid为1,是不会理会kill signal信号的。
-
如果一个进程退出时,它还有子进程存在,被称为孤儿进程,那么这些孤儿进程会重新成为init进程的子进程,转由init进程来管理这些子进程,包括回收退出状态、从进程表中移除等。
-
如果init进程跪了,那么所有用户进程都会被退出。
与孤儿进程类似的是僵尸进程,清理僵尸进程的方法,是杀掉不断产生僵尸进程的父进程,然后这些僵尸进程会称为孤儿进程,由init进程接管、回收。
进程应用
进程间通信
谈到通信我们都知道,通信的双方必须存在一种可以承载信息的介质,对于计算机之间的通信来说,这种介质可以是双绞线、光纤、电磁波。那对于进程间的通信呢?这种介质有哪些呢?在Linux中,满足这种条件的介质,可以是:
- 操作系统提供的内存介质,比如共享内存、管道、信号量等。
- 文件系统提供的文件介质,比如UNIX域套接字、文件等
- 网络设备提供的网卡介质,比如socket套接字。
- 等等。
对于操作系统提供的介质来说,常用的有
- 信号量机制
- 匿名管道(仅限父子进程)与有名管道
- SysV和POSIX
- 消息队列
- 共享内存
- 等等
优缺点介绍:
- 信号量:不能传递复杂消息,只能用来同步
- 匿名管道:容量有限速度较慢,只有父子进程能通讯
- 有名管道:任何进程间都能通讯,但速度较慢。
- 消息队列:容量受到系统限制,有队列的特性,先进先出。
- 共享内存:速度快,可以控制容量大小,但需要进行同步操作。
它们的用法相对较为简单,在需要使用时查阅相关文档即可,共享内存是比较常用的做法。
信号处理
信号最早是在Unix系统被引入,它主要用于进程间的通信,同时进程可以主动注册信号处理函数,来检测或者应对系统发生的事件。比如当进程访问非法地址空间时,进程会收到操作系统发送SIGSEGV信号,默认情况下的处理方式是:该进程会退出并且把堆栈dump出来,简称出core。
总的来说信号的主要目的:
- 让进程知道已经发生的特定事件。
- 强迫进程处理这个特定事件。
目前Linux支持的信号,已经默认的处理函数,可以在man手册中查到,截图如下:

比较常见的信号,解释如下:
- SIGCHLD: 一个进程通过
fork函数创建,当它结束时,会向父进程发送SIGCHLD信号。 - SIGHUP: 挂起信号,当检测到控制终端,或者控制进程死亡时。比如用户退出shell终端时,该shell启动的所有进程,都会收到这个信号,默认是终止进程。
- SIGINT:当用户按下Ctrl+C组合键时,终端会向该进程发送此信号,默认是终止进程。
- SIGKILL: 常用的kill -9指令会发送该信号,无条件终止进程,本信号无法被忽略。
- SIGSEGV: 进程访问了非法的内存地址,默认行为是终止进程并产生core堆栈。
- SIGTERM: 程序结束信号,该信号可以被阻塞和忽略,通常标识程序正常退出。
- SIGSTOP: 停止进程的执行,该信号不能被忽略,默认动作为暂停进程。
- SIGPIPE: 当往一个写端关闭的管道或socket连接中连续写入数据时会引发SIGPIPE信号,引发SIGPIPE信号的写操作将设置errno为EPIPE。在TCP通信中,当通信的双方中的一方close一个连接时,若另一方接着发数据,根据TCP协议的规定,会收到一个RST响应报文,若再往这个服务器发送数据时,系统会发出一个SIGPIPE信号给进程,告诉进程这个连接已经断开了,不能再写入数据。
其实在项目开发中,常常会和信号处理打交道。比如在处理程序优雅退出时,一般需要捕获SIGINT、SIGPIPE、SIGTERM等信号,以合理的释放资源、处理剩余链接等,防止程序意外crash,导致的一些问题。
后台进程与守护进程
在接触Linux系统时,常常会遇到后台进程与守护进程,这里简单的介绍一下这两种进程。
-
后台进程:通常情况下,进程是放置在前台执行,并占据当前shell,在进程结束前,用户无法再通过shell做其他操作。对于那些没有交互的进程,可以将其放在后台启动,也就是启动时加一个
&,那么在该进程运行期间,我们仍是可以通过shell操作其他命令。不过当shell退出时,该后台进程也会退出。 -
守护进程:如果一个进程总是以后台的方式启动,并且不能受shell退出的影响而退出,那么可以将其改造为守护进程。后续进程是系统长期运行的后台进程,比如mysqld、nginx等常见的服务进程。
那么这两者有啥区别呢?
- 守护进程已经完全脱离终端,而后台进程并未完全脱离终端,即后台进程仍是可以输出到终端的。
- 在终端关闭时,后台进程会收到信号退出,但是守护进程则不会。
举个例子,通过./spider &在后台执行抓取任务,但没过多久,终端自动断开,导致spider进程中断退出。
在进一步了解守护进程之前,还需要了解一些会话和进程组的概念。
- 进程组:由一系列相互关联的进程组成,由PGID来标识,一般是进程组创建进程的PID。进程组的存在是为了方便对多个相关进程执行统一的操作,比如发送信号量给统一进程组的所有进程。
- 会话:由若干个进程组组成,每一个进程组从属于一个会话,一个会话对应着一个控制终端,该终端为会话所有进程组的进程所共用,其中只有前台进程组才可以与终端交互。
那如何实现一个守护进程呢?
- 在后台运行:fork出子进程A,当前进程退出,保留子进程A。
- 脱离控制终端:目的是摆脱终端的影响,通过
setsid()重新为子进程A设置新的会话。 - 禁止子进程A重新打开终端:因为设置新会话之后的进程A,是进程组的组长,所以它是有能力重新申请打开一个控制终端。通过再次fork子进程B,并退出进程A,B不再是进程组组长,也无法打开新的终端。
- 关闭已打开的文件描述符、改变工作目录等等。
- 处理SIGCHILD信号:由于守护进程一般是长期运行的进程,当产生子进程时,需要处理子进程退出时发送的SIGCHILD信号,不然子进程就会变成僵尸进程,从而占据系统资源。
总结来说,守护进程是一种长期运行于后台的进程,它脱离了控制终端,不受用户终端退出的影响。可以通过nohup操作,将一个进程变成守护进程执行。比如nohup ./spider &,这样即使终端断开后,spider进程仍会继续执行。
浅谈nginx多进程模型
nginx是一款高性能的Web服务器,由于它优秀的性能、成熟的社区、完善的文档,受到广大开发者的喜爱和支持。它的高性能与其架构是分不开的,nginx的框架如下图所示:
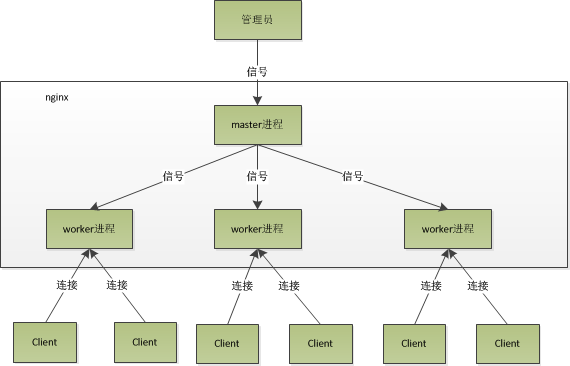
Nginx是经典的多进程模型,它启动以后以守护进程的方式在后台运行,后台进程包含一个master进程,和多个worker进程。其中master进程相当于控制进程,有以下作用:
- 接收外界信号执行指令,包括配置加载、向worker发指令、优雅退出等等。
- 维护worker进程的状态,当worker进程退出后,自动启动新的worker。
其中 master 进程支持的信号处理如下:
- TERM、INT:快速退出
- QUIT:优雅退出
- HUP: 变更配置,用新配置启动worker,优雅关闭老的worker等。
- USR1: 重新打开日志文件
- USR2: 升级二进制文件(nginx升级)
- WINCH: worker进程的优雅退出
单个worker进程也支持信号处理,包括:
- TERM、INT: 快速退出
- QUIT: 优雅退出
- USR1: 重新打开日志文件
- WINCH: 终端调试等
worker进程基于异步非阻塞的模式处理每个请求,这种非阻塞的模式,大大提高了worker进程处理请求的速度。为了尽可能的提高性能,nginx对每个worker进程设置了CPU的亲和性,尽量把worker进程绑定在指定的CPU上执行,以减少上下文切换带来的开销。由于这种绑核的模式,一般推荐worker进程的数目,为CPU的核数。
nginx使用了master<->worker这种多进程的模型,有哪些好处呢?
- worker进程间很少共享资源,在处理各自请求时,几乎不用加锁,省掉了锁带来的开销。
- worker进程间异常不会相互影响,一个进程挂掉之后,其他进程还在工作,可以提高服务的稳定性。
- 尽可能的利用多核特性,最大化利用系统资源。
常用工具介绍
Linux内置了许多工具,用于排查系统问题和查看资源使用情况,这里简单介绍和进程有关的几个工具。
ps: 查看进程的基本属性
常用的参数如下:
- ps aux : 查看所有进程的基本信息
- ps -p $pid : 查看指定pid的进程
- ps -fp $pid : 打印的进程信息较全
- 自定义打印进程的信息:例如
ps -C nginx -o pid,ppid,rsz,vsz,pcpu: 打印nginx进程的pid、ppid、实存、虚存、cpu。 - ps axjf:查看进程树:,使用
pstree -p $pid更加直观 ps -T -p $pid或者ps -Lf $pid: 查看进程的线程信息- 等等
除了通过ps获取进程的信息外,还可以通过/proc文件系统来查看进程的基本信息:
- /proc/$pid/cmdline: 进程的命令行参数
- /proc/$pid/cwd: 当前工作目录
- /proc/$pid/environ: 环境变量值
- /proc/$pid/exe: 软链到二进制执行程序。
- /proc/$pid/fd: 包含所有的文件描述符。
- /proc/$pid/maps: 内存映射,包括二进制和lib文件。
- /proc/$pid/mem: 进程的内存
- /proc/$pid/stat: 进程状态
- 等等
lsof: 查看进程打开的文件情况
有两个场景:
- 场景一:机器上一个文件大小不停的增长,导致磁盘空间一次又一次的爆满,如果这时候你想把写文件的罪魁祸首进程找到,那应该怎么做呢?
- 场景二:发现磁盘已经快满了,通过rm -f 删除一些大文件,但磁盘空间并没有明显减少,这个时候应该怎么做呢?
对于这些场景,我们可以借助lsof命令,
- 对于场景一来说:可以查看该文件被哪个进程打开,找到罪魁祸首进程,然后对其处理。
- 对于场景二来说:如果这个文件被其他进程打开,通过rm -f是无法真正删掉一个文件的,还需要杀掉打开该文件的进程,以关闭文件描述符,那么文件才能真正被清理。
lsof的常见用法如下:
- 查看特定用户打开的文件列表:
lsof -u xxx - 查看特定端口打开的文件列表:
lsof -i 8080 - 查看特定端口范围打开的文件列表:
lsof -i :1-1024 - 基于TCP或者UDP查看打开的文件列表:
lsof -i udp - 查看特定进程打开的文件列表:
lsof -p $pid - 查看打开特定文件的进程列表:
lsof -t $file_name - 查看打开特定目录的进程列表:
lsof +D $file_path - 等等
netstat: 查看网络连接情况
netstat是一个监控TCP/IP网络非常有用的工具,它可以显示路由表、网络连接、网络接口设备状态等信息。输出的信息类型由第一个参数决定:
- (none): 默认情况下,netstat会显示打开的socket列表。
- –route,-r: 显示内核的路由表,和 -e 的输出相同。
- –group,-g: 显示IPv4和IPv6的多播组成员身份信息。
- –interfaces, -i: 显示网络接口状态。
- –statistics, -s: 显示每一种协议的统计信息。
下面列举各个场景的使用用法:
- 仅显示数字地址:netstat -n
- 仅显示tcp链接:netstat -t
- 仅显示udp链接:netstat -u
- 仅显示监控socket链接:netstat -l
- 显示进程的名字和PID:netstat -p
strace: 查看系统调用情况
strace用来跟踪进程执行时的系统调用和所接收的信号。在Linux中,进程是无法直接访问硬件设备的,当访问硬件设备时,必须要切换至内核态模式,通过系统调用来访问硬件设备。
strace可以跟踪到一个进程产生的系统调用,包括参数、返回值、执行消耗的时间。每一行的输出,左边是系统调用的函数名和参数,后面是调用的返回值。用法如下:
1 | -c 统计每一系统调用的所执行的时间,次数和出错的次数等. |
当服务器卡顿时,可以通过strace系统调用查看特定进程的系统调用执行情况:
1 | strace -c -tt -o ./server.log -p 26844 |
输出如下:
1 | % time seconds usecs/call calls errors syscall |